

Importing data from websites into documents or spreadsheets is known as “data scraping,” sometimes called “web scraping.” Data is taken from the web and reused on other websites or utilized for the scrape operator’s benefit. There are several software programs available that can automate data scraping.
Data scraping is commonly used to:
- Gather business information to inform your site’s content.
- Identify costs for travel comparison or booking websites.
- Obtaining sales leads or conducting market research using public data sources
- Send product data from e-commerce websites to online marketplaces such as Google Shopping.
Although data scraping has legitimate applications, dishonest people regularly take advantage of it. For instance, data scraping is widely used to collect email addresses to spam or defraud individuals. Likewise, scraping allows for the automated publication of protected material from one website to another. Automated email harvesting is prohibited in several countries and is often seen as an unethical marketing tactic.
Many different firms employ data scraping technologies, but not always with nefarious intent. These include customization, web content and design, business intelligence, and marketing research. Data scraping may be used to reveal and exploit sensitive data, which presents problems for many firms. The website being scraped may be unaware that any data is being gathered about it or what is being collected. Similarly, a trustworthy data scraper could not save the information securely, giving hackers access. Web scraping data may be used by bad actors to launch cyber attacks if they have access to it. For instance, criminals may utilize the data they have scraped to carry out the following:
Attackers might use data that has been scraped to improve their phishing methods. They can determine who is more vulnerable to phishing attacks or which employees have the access rights they wish to target. Attackers can carry out spear phishing attacks that are specifically targeted at their target if they can discover the names of top workers. Password cracking attacks: even if passwords aren’t explicitly disclosed, attackers can use credentials to bypass authentication mechanisms. They can research information that is readily accessible about your personnel to determine passwords based on personal information.
Data scraping methods
Here are a few methods frequently used to extract information from websites. In general, online scraping methods collect material from websites, run the processed content through a scraping engine, and produce one or more data files containing the content.
HTML Parsing
JavaScript is used to target a linear or nested HTML page during HTML processing. It is an effective and quick technique for scraping screens, retrieving resources, and collecting information and links (such as a nested link or email address).
DOM Parsing
The Document Object Model (DOM) defines the format, content, and organizational elements of an XML file. Scrapers commonly utilize a DOM parser to examine the complex layout of internet sites. DOM parsers may be used to access the information-containing nodes and scrape the website using tools like XPath. Web browsers like Firefox and Internet Explorer may be used by scrapers to capture whole web pages for dynamically generated content (or parts of them).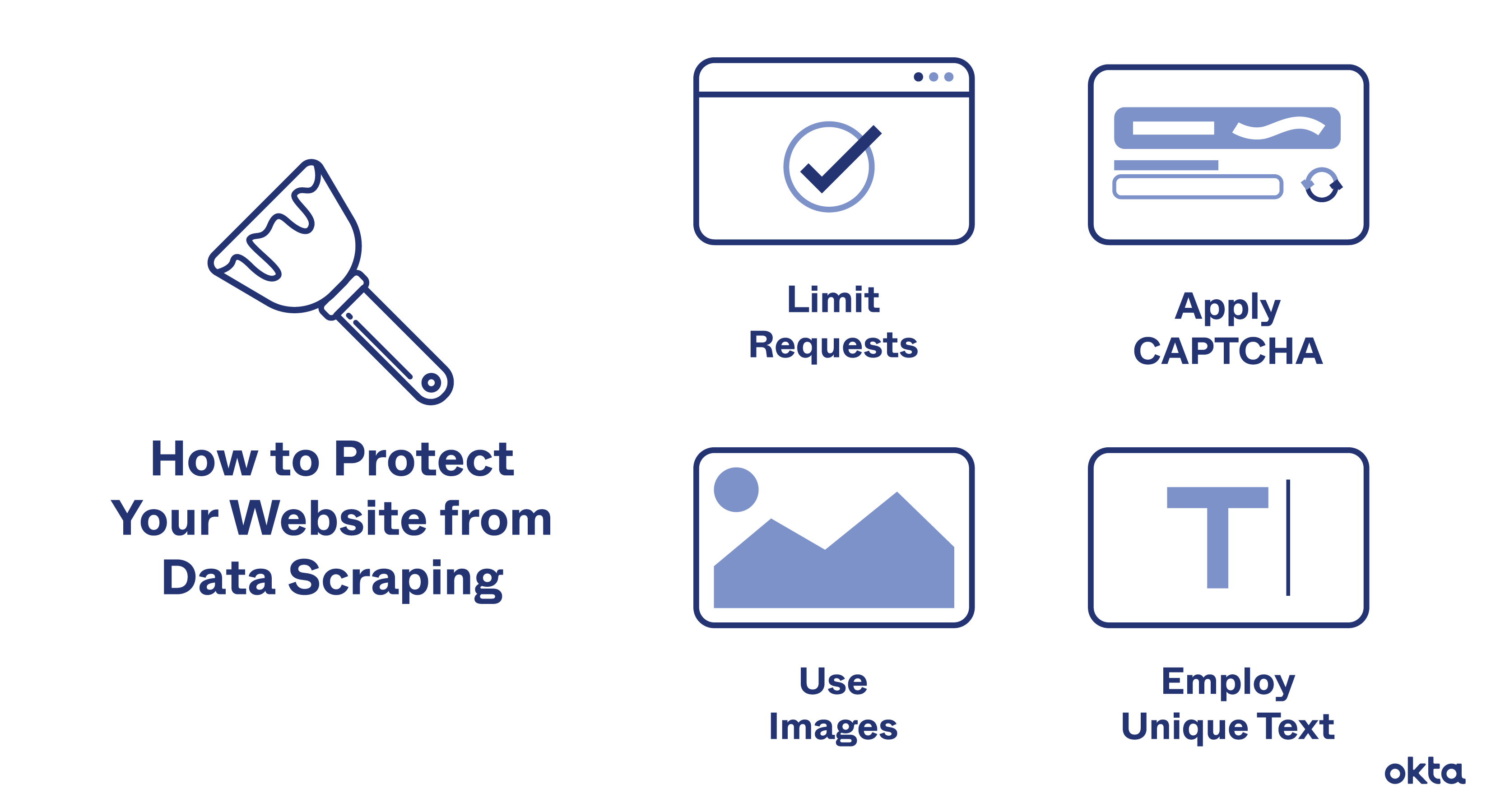
Vertical Aggregation
Businesses may create vertical aggregation platforms employing sophisticated computer capabilities to target certain verticals. With little to no human intervention, these data-collecting systems may be utilized to autonomously develop and manage bots for some sectors. The information required for each vertical is used to develop the bots, and the effectiveness of the bots depends on the quality of the data they gather.
XPath
The abbreviation XPath stands for XML Path Language, a querying language for XML documents. Scrapers can utilize XPath to browse through XML documents’ tree-like structures by choosing nodes based on different criteria. To extract whole web pages and post them on a target site, a scraper may combine DOM parsing with XPath.
Google Sheets
A common tool for data scraping is Google Sheets. If scrapers wish to extract a certain pattern or piece of data from a website, they can use Sheets’ IMPORTXML method to do it. Additionally, with this command, you may determine whether a website is secure from scraping or not.
How to Prevent Web Scraping
Web material often has to be uploaded to the website viewer’s computer to be seen. This implies that a scraping bot can access any information that the viewer can. The following techniques can be used to limit the quantity of information that can be scraped from your website Human website users engage with websites at a comparatively predictable rate. A human cannot, for instance, browse 100 online sites in a second, but computers can send out many requests at once. The frequency of queries may be a sign that data scraping methods are being used to quickly scrape your whole website.
An IP address’s ability to make a certain number of requests in a certain period might be rate limited. This will shield your website from abuse and greatly reduce the rate at which data scraping may take place. Applying CAPTCHAs is another way to impede data scraping activities. These ask website users to do a job that is manageable for a person but prohibitively difficult for a computer. Even if a bot manages to bypass the CAPTCHA just once, it won’t be able to do it repeatedly.
The disadvantage of CAPTCHA difficulties is that they could have a poor user experience. For a data scraping bot to efficiently navigate a website and interpret meaningful information, it needs a consistent layout. By routinely altering HTML markup elements, you may stop a bot in its tracks.
For instance, you may alter different markup components or nest HTML elements, which will make it more challenging to constantly scrape. To secure their content, some websites apply randomized changes each time they are shown. Instead, websites can alter their markup code less often to thwart a longer-term data scraping operation.
This less prevalent mitigation strategy makes use of images from the media. Since the data cannot be extracted from picture files as a string of characters, optical character recognition (OCR) is necessary. This makes it much harder for data scrapers to copy the text, but it can also be a barrier for real internet users because they will have to enter it in again or remember it instead of being able to copy content off the website.
However, the aforementioned techniques are imperfect and do not provide safety against scraping. Use a bot security system that can identify scraping bots and prevent them from connecting to your website or web application to properly safeguard your website.
For years, Meta scraped websites despite opposing the practice.
Years ago, Meta Platforms Inc., the company that owns Facebook, hired a contractor to collect data from other websites while denouncing the practice in public and suing businesses that used its social media platforms to do so. Legal records in a California court action in which the social media behemoth sued the Israeli data collection firm Bright Data for gathering and selling information gleaned from Facebook and Instagram revealed Meta’s scraping.
Meta spokesperson Andy Stone revealed that Meta had engaged Bright Data to collect information from e-commerce websites to create brand profiles on Meta platforms, but he would not specify which websites were scraped. According to him, Meta utilized Bright Data to discover “harmful websites” and “phishing activities.”
Many businesses use internet scraping to get information that might aid in pricing comparison, audience research, competition tracking, and market trends. However, if businesses don’t take steps to stop it through technological and legal methods, scraping can pose a privacy issue when it targets personal information like contact data and violates EU legislation. The EU penalized Meta €265 million ($277 million) in November for failing to take reasonable steps to prevent unauthorized access to customer data.
On January 6, Meta launched legal action against Bright Data in San Francisco. An email conversation between representatives of Meta and the CEO of Bright Data, Or Lenchner, is one of the papers supplied.
edited and proofread by nikita sharma



